
Zero SEO Headaches

This is part 8 of a 12-part series called Distilling the Web to Zero. The web is far from done improving - particularly as it pertains to building rich web applications that are, to users, developers, and businesses alike, more desirable than their native-app counterparts. This series is prefaced by defining the biggest challenges on the road towards that goal and the 12 essays that follow explore potential solutions using concrete examples.
Zero SEO Headaches
"Float like a butterfly, sting like a bee."
– Muhammad Ali
SEO through the generations
The web1 era was dominated by server-rendered HTML and was a boon for search engines since it was trivial to GET, parse, index, and follow links. The web2 era is far less accommodating since it consists largely of client-rendered SPAs. Native apps are downright SEO-hostile, but most companies don’t seem to mind since a native app’s typical use case is more utility-oriented, and less content-based (social-media being a giant exception, of course).
Where does web4 and its native-like, web-based apps stand in terms of SEO? Good news! Since it operates on server-rendered HTML it’s highly SEO-friendly. And due to its remarkable speed and zero cache-misses, it comes with advantageous SEO scores.
However, anybody that read last month’s essay about nullipotent GETs might be wondering how can any dynamic content be included in the response when all thread-blocking and all async communications are disallowed for all GET requests.
There are two options.
Float it in RAM
As mentioned previously, web4 will more closely resemble video games than websites. The way it treats content is one such example. Upon launching a web4 process, it can use various lifecycle events to “generate world” or “build terrain” (to steal a Minecraft reference). This only needs to happen once during process-launch, not for every request. Should any GET requests come in during this “loading stage,” a loading screen will be necessary until it completes.
Once loaded however, web4 apps benefit from breathtaking speed gains since RAM is 5,000x faster than a network round trip in the same data center. What’s more, when content is held in RAM instead of on a separate cache server, it’s no longer forced to be passive and inert. Suddenly, content can react to state changes in ways that bring compelling new real-time use cases that were previously too difficult or too expensive to be worthwhile.
web4’s major SEO benefit comes from never experiencing any “cache misses” – a common occurrence when web crawling through prior web generations. When all content is floated in RAM on The Edge, SEO is never penalized from the overhead of needing to travel upstream back to the origin servers.
Square peg, round hole
Historically, floating your entire dataset in RAM is a very foreign concept in the world of web development. Today’s web ecosystem, from our languages, our hosting infrastructure, even our protocols were never designed to handle this use case well. Scripting languages, like PHP, Perl, Ruby, Python and JavaScript were all designed for short, batch-like tasks and less for reaching maximum uptime. Many cloud services offer elastic scalability by way of short, ephemeral, stateless executions that are spread out thinly across horizontal load balancing. HTTP even celebrates statelessness as a core strength of the protocol. None of these are very accommodating to a use case that requires a lengthy initial load time.
That’s not meant to imply that web4 is a bad idea however, just that its ecosystem will look remarkably different from web2’s ecosystem. Instead of scripting languages, web4 will leverage lower-level, multi-threaded languages like C#, Java, Kotlin, Swift, Rust and Go which have the ability to take advantage of the full machine from a single process instead of process-sharding which is crucial when floating large datasets in RAM. Further, instead of leveraging clusters of many small, ephemeral runtimes, web4 will use a single, but larger, dedicated server. Workloads won’t be load balanced horizontally but rather segmented by responsibility, like choosing a game server to host a short-lived tournament. Instead of simple request/response protocols like HTTP, web4 will take hard dependencies on stateful, bidirectional channels like WebSockets.
Isn’t RAM expensive?
It certainly varies. AWS is happy to sell you 1 TB of RAM for up to $108k / year while Amazon.com is happy to sell you a 2U server with 1 TB of RAM for only $1.5k! RAM has a notorious premium in The Cloud. Reasons for this might stem from the fact that, while the CPU was easy to share (and oversubscribe) by way of virtualization (EC2), operating systems still required a pre-allocated and unshareable amount of RAM whether it got used or not. This created more scarcity in RAM that you didn’t see in the CPU. However newer innovations in virtualization, like microVMs and ballooning, will help normalize this disparity by creating more options for resource sharing, such as virtualizing at a container-level instead of OS-level thus bringing memory overhead to under 5MB as opposed to a typical 4GB for a full OS. This is how newer cloud services like Lambda and Fargate achieve their higher levels of resource efficiency.
Besides, you might be surprised to discover just how little RAM you might need.
Examples please
As a concrete example, let’s take one of my favorite bloggers, Scott Hanselman. Blogging since 2002, he has nearly 4000 posts. Assuming an average post size of 8KB (UTF8-encoded), with an average of 15 comments per post at roughly 200 characters each – floating over 20 years of his content in RAM would require a grand total of only 45 MB!
That’s shockingly small. To draw a comparison, Slack and Jira both send roughly 50MB of JavaScript to each browser for each uncached request! That makes in-RAM floating seem trivial in comparison. A hello-world Node.js application will happily consume anywhere between 85MB - 600MB of RAM!
Even large publications like TechCrunch which write 1,000 articles every month for a span of 20 years could float their entire library in my laptop’s RAM.
Even that $1,536 server mentioned above could float every single The New York Times article ever written (13 million) and still have enough RAM left over to float 9 more of its competitors.
Bigger than RAM
Some apps, however, simply cannot fit their entire dataset in RAM. The good news is that web4 adopts a far richer lifecycle model than a primitive request-response approach. web4 is designed for long-lived executions (measured in months or years) while maintaining thousands of persistent, stateful connections that come and go for the duration of users’ sessions. Therefore web4 apps adopt a lifecycle model that more closely resembles an iOS scene or Android activity (except inherently multi-user, of course).
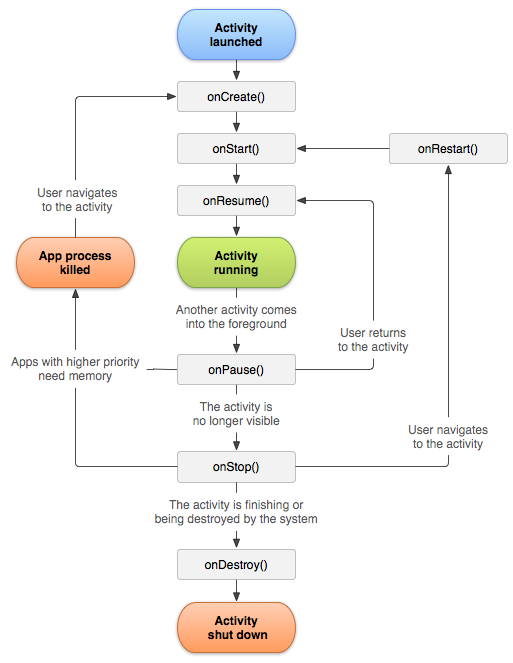
This offers a much greater level of flexibility. For example, to handle bigger-than-RAM datasets without compromising SEO, some interactions can be handled differently than the default path. Specifically, by inspecting the user agent for the presence of a bot (like a web crawler or an unfurling service), it can conditionally delay a GET’s rendering until after the completion of the lifecycle stage responsible for all fetches and async communication which is usually reserved for after a WebSocket connection is established. Such change can be accomplished by configuration only, no code changes necessary.
Artifacts
Source code: github.com/xui/xui
Member discussion