
Zero JavaScript


The purpose of this series was to explore the idea maze of what the web might look like if it were rebuilt from first principles given the internet infrastructure we have today. The goal was to force clarity to a mess of unrefined ideas by putting them into words as a new essay each month of 2024. Afterward came implementation and not every idea survived first contact with reality. Even the names themselves changed: XUI became Web4, HTTP/X became Keyholes, and ZeroScript became XTML (ironic considering the "zero theme" of the series). This work eventually led to the formation of The Web4 Foundation.
Zero JavaScript
The next generation of the web will be built with zero JavaScript. Instead, we’ll see a rise in general-purpose and lower-level languages like C#, Java, Kotlin, Swift, Go, and Rust. This will be accomplished, not with WebAssembly, nor with server-side rendering but, with a new, edge-native paradigm called server-side event handling.
How could anybody be so sure? Well, we’ve seen this movie before.
History repeats itself
“It's time to blit or get off the pot."
– John Siracusa
The year was 2001. It had been 17 years since the concept of a GUI became mainstream but it was starting to show its age. Most traditional windowing systems used a “switch-model" where each running program would take turns drawing their own pixels into a shared location in RAM (a backing store) which would eventually get flushed to the video card. This approach had shortcomings. Since all programs shared the same backing store, windows were forced to be strict rectangles or overly simplistic shapes. Rounded corners were avoided. Holes were simply ignored or required taxing hacks. Any translucency was out of the question since each pixel of the screen was technically “owned” by only one program at a time. Shadows were used sparingly since that required doing a “second pass” over the backing store which added a noticeable burden on the CPU. Simple things like motion were computationally intensive since it required drawing the same pixels repeatedly but into offset regions of the backing store which explains why resizing or moving a window across the screen was communicated using rectangular outlines instead of the full, opaque window.
Eventually, users’ appetite for richer graphical experiences outpaced what the CPU could handle gracefully. Meanwhile, thanks to the popularity of 3D gaming, GPUs were starting to become quite powerful. Mac OS X, launched in 2001, was a brand new “from-scratch” OS and Apple had a master plan to unlock an ocean of new, mind blowing graphical capabilities via Quartz, its display layer. It involved treating every window like a 2D surface in a 3D environment each using its own separate backing store as the texture map for that polygon. The GPU could then effortlessly composite each layer into a single scene faster than a CPU could ever dream of doing.
Sounds too good to be true? For the first few years, it was. Transplanting the GUI from the CPU to the GPU meant everything had to change. The biggest challenge was rasterization – the process of converting shapes into pixels – because this step was currently incompatible with GPUs. This is why Apple required every single software vendor to port every single app to Cocoa – a tall order, to say the least. Cocoa’s secret sauce was Quartz 2D – instead of rasterizing a small number of shapes into millions of pixels on the CPU side only to immediately copy them to the GPU side, Cocoa would simply send tiny drawing commands over the wall to the GPU so it could handle the rasterization itself. This was the key to unlocking a game-changing amount of performance-rebalancing since it not only relieved the CPU of its rasterization duties but it also no longer required repeatedly copying giant backing stores over the wall to the GPU.
Until this goal could be reached, though, Mac OS X existed in a worst-of-both-worlds state using a temporary compatibility layer called Carbon, forced to straddle the fence between the CPU and GPU so it could perform half the work on the CPU (rasterization) and the other half of the work on the GPU (compositing) which also required a massive IO tax over the AGP bus. This led to the perception of Mac OS X being unbearably slow and a huge resource hog. The migration was bumpy and long (and Adobe famously dragged their feet on porting Photoshop until 2010) but eventually it was more than worth it because what resulted was incredibly sophisticated effects, buttery smooth frame rates, and a nearly idle CPU.
“If you're going through hell, keep going.”
– Winston Churchill
Note:
If you enjoy a good story about graphics processing check out John Siracusa’s fantastic and very detailed breakdown of Quartz and the transition to a hardware accelerated GUI (only pages 13 and 14 specifically).
The web is in the middle of a similar transition. It also has been 17 years since JavaScript and its single-page apps started increasing the richness of the web. Like Carbon, however, it’s forced to split its workload across two very separated worlds (browser and server) forcing it to only ever be a temporary compatibility layer until something better could come along. (Similar to Cocoa, completing this transition also involves sending tiny drawing commands over the wall. This is the problem HTTP/X solves, but more on that later.) For now, it’s important to understand why JavaScript has not only failed to keep pace with native apps but why it’s impossible for it to ever catch up.
JavaScript has a payload problem
I fell in love with JavaScript back in ‘98. The web wouldn’t be a fraction of what it is today without it and it’s been a pleasure watching it mature across multiple innovation cycles. To give credit where it’s due, JavaScript has improved 100x all things considered. All things except one.
JavaScript has a payload problem.
On bloat
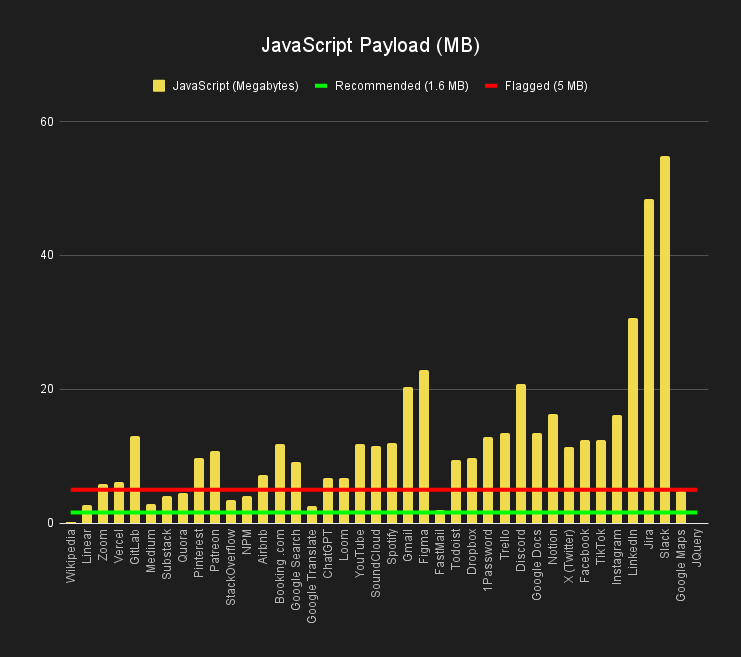
Google’s Chrome team recommends avoiding enormous network payloads and provides guidance on keeping total byte size below 1,600 KiB. Their Lighthouse tool will even flag pages that exceed 5,000 KiB. Nikita Prokopov wrote a very entertaining article called JavaScript Bloat in 2024 that measures the JavaScript payloads of 40 popular websites. Only 2 of them pass the recommended size and the majority of them fail the upper bound by a large margin.
The issue goes deeper than just networking too. The Chrome team wrote an incredible article explaining the CPU’s role called The Cost of JavaScript. Ryan Carniato shows an example where, even after downloading a relatively tiny 170 KB of JavaScript, a low end mobile device still took 3.5 seconds to process, parse and execute the code.
On-demand
JavaScript’s “payload problem” technically isn’t even its own fault. It has nothing to do with the language itself and everything to do with the on-demand nature of the web. It’s one of the defining differences between webapps and native apps: native apps benefit from preloaded UI while a webapp’s UI is loaded on-demand.
This payload problem also explains why WebAssembly, now 7 years old, has yet to displace JavaScript for anything except for some very experimental use cases. It does offer language-optionality (a core theme of this series) but since WebAssembly is also subject to the on-demand nature of the web, the core “payload problem” persists.
The sophistication ceiling
The issue with an on-demand approach is more profound than just slow load-times though. Careful caching can help mitigate some of that. The bigger issue is that it imposes a “sophistication ceiling” on all webapps. For mature webapps, a massive amount of effort is wasted on code-triage and suffering the cost-benefit analysis of justifying the existence for each line of code. It’s a terrible way to live. It forces a scarcity mindset upon the developer. It feels like counting beans. Dependencies are evaluated based on their size more than their merit. It results in sacrificing UI-polish and compromising your UX all for the sake of payload budgets. This sophistication ceiling imposes a handicap on webapps and makes it impossible to keep up with their native app counterparts.
Meanwhile, building a native app is a shockingly different experience. In those ecosystems, developers build with an abundance-mindset instead of a scarcity-mindset. Initially the differences might seem minor, but these little things compound over time and in the long run, the difference in outcomes is enormous. It’s a seriously unfair advantage. It creates a pattern of UX-disparity between web/native that both users and developers have falsely come to believe is simply unavoidable. This sentiment has reached a point where the conversation about how to make webapps feel more native isn’t being discussed anymore. Just this April, Chrome v12 has even removed the PWA category from Lighthouse.
It’s getting worse, not better
Won’t this problem fix itself if we just wait for innovations in networking and processor speeds to inevitably catch up? Unfortunately no. Since software is eating the world it’s rare to find examples where software doesn’t gladly saturate the full capacities that hardware will allocate to it.
Payload sizes are accelerating not slowing, and it’s outpacing the growth of networking infrastructure. 2023 saw an average JavaScript payload growth of 17%. Before that, the annual growth rate was 6%. 2024 is currently 20% higher than 2023 and it’s only June!
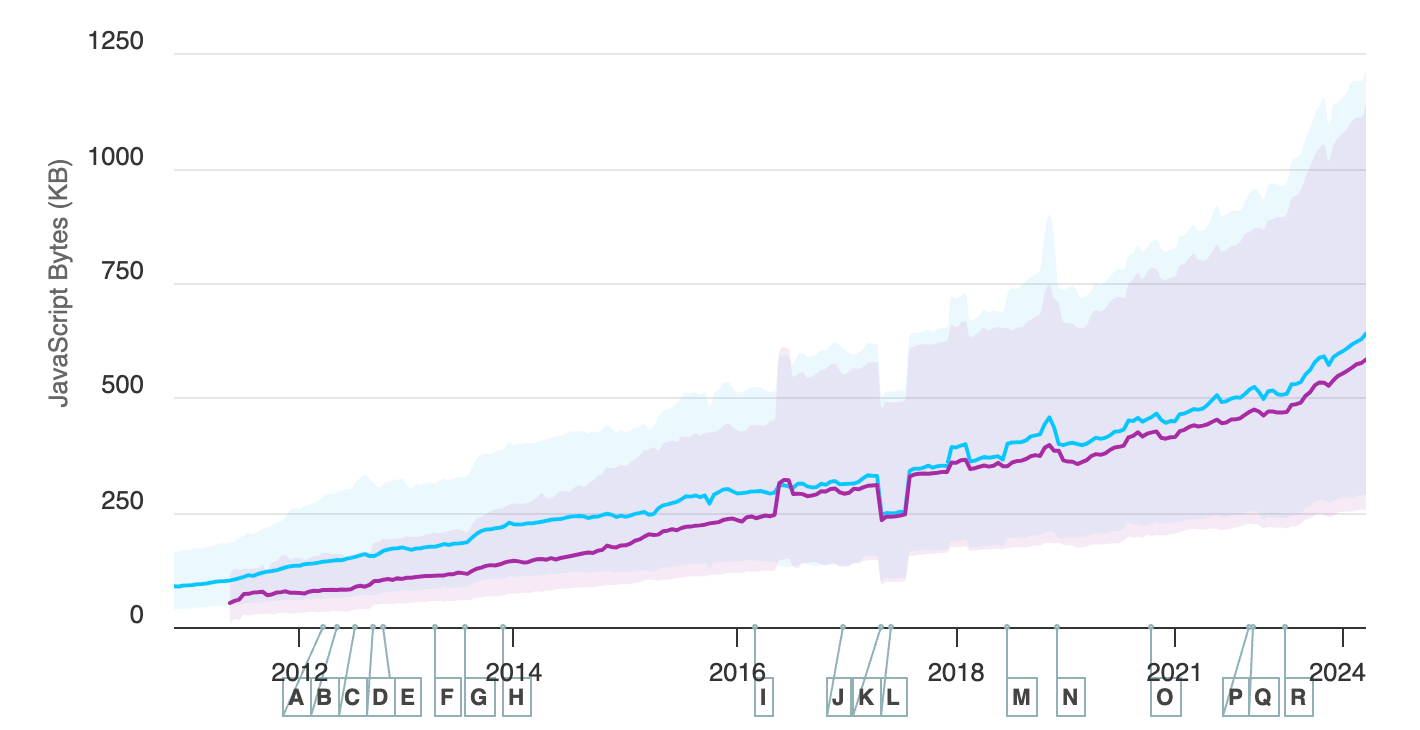
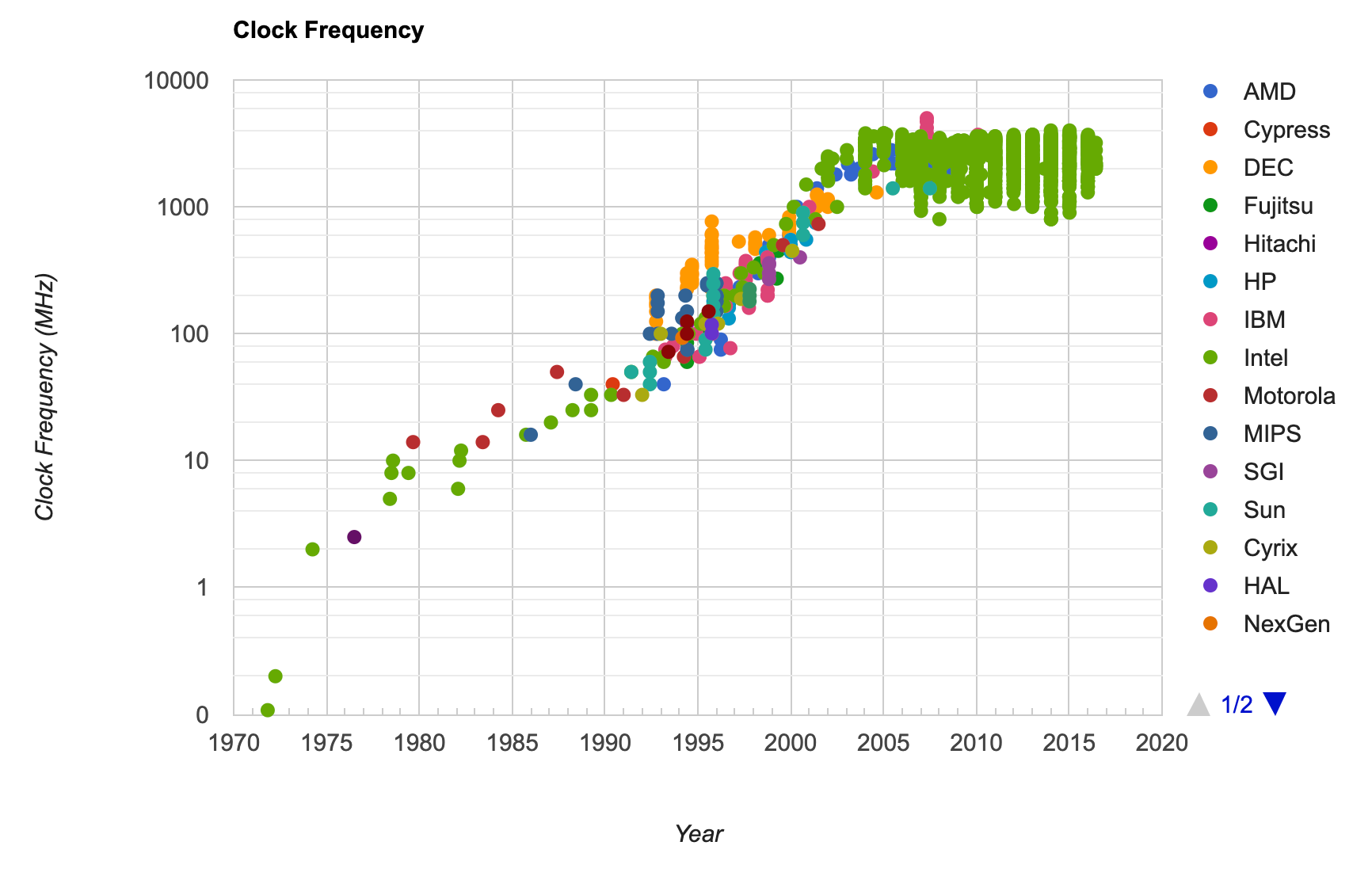
Some aspects of JavaScript, like parsing and compiling, have benefited from CPU innovations like the ever-increasing number of cores in each processor. Unfortunately the job of rendering UI is something that must be handled from the main thread only and therefore cannot benefit from parallel hardware. Clock frequencies have notoriously been stuck in time for the past 20 years! Granted, there’s more to CPU speed than just clock frequencies but workloads that cannot be divided (such as rendering UI) are now several generations behind at this point.
End-of-life(cycle)
Innovation follows an s-curve pattern where one particular approach gets incrementally better and better… until it doesn’t. Technological progress alternates between incremental innovations followed by disruptive innovations, and back again.
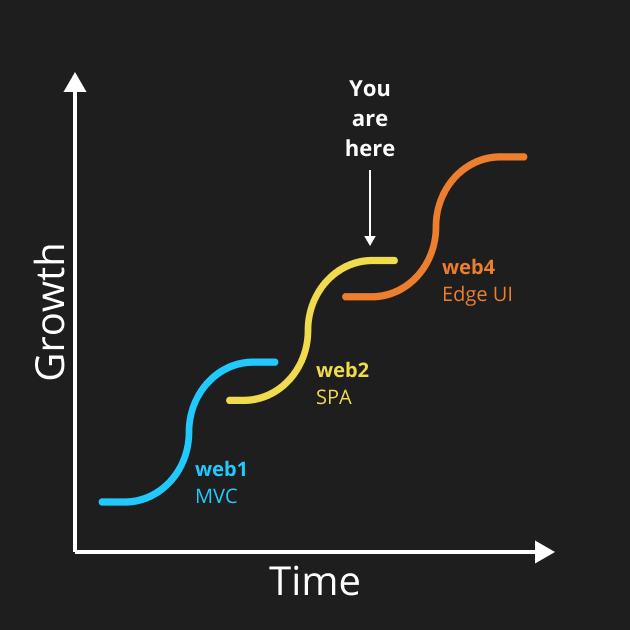
Note:
web3 is intentionally left out of this chart. While web3 does represent a generational evolution of the web concerning zero-trust concepts, it isn’t related to browsers, UI, or webapps – the core context of this essay.
It’s unrealistic to expect something to improve to infinity – everything either eventually reaches peak performance or gets replaced by a generational shift. One sign that you’re nearing the end of this s-curve is when you see an explosion in complexity required to accomplish ever-diminishing gains. The end of an era is not all bad, though. Performance engineers thrive in this stage, where constraints are well known and the target stops moving. Formula One racing comes to mind – very exciting; not very practical.
The current state of the web is similarly not very practical.
The latest innovations in web development squeeze minor speed improvements at the cost of great complexity, for example, progressive hydration, partial hydration (islands), resumability, SSR, server components, code splitting, lazy loading, tree shaking, progressive enhancement.
Fascinatingly, all these innovations have one thing in common – JavaScript-avoidance.
Sure, innovation is a messy process, but in terms of navigating the idea maze, you know you’re headed towards a dead end when the path you’re on is defined by limiting the resource you need the most. A scarcity mindset eventually leads to failure. When what you really need for success is more JavaScript but every new innovation is a creative way to use less JavaScript, you have a catch-22. The web needs its equivalent “Quartz moment” before it can operate with a mindset of abundance.
The only winning move
“The only winning move is not to play.”
– WarGames (1983)
Nature imposes a maximum size for each species. This is due to isometric scaling which is governed by the square-cube law. In short, it explains how, as an object grows, its surface area will increase exponentially compared to its length, and its mass will grow exponentially compared to its surface area. For animals, this creates a mismatch between biological systems. An elephant twice as long would suffocate, having eight times more tissue to support but only four times the respiratory surface area to support it. While ants might be able to lift 50 times their body weight; an ant the height of a human risks snapping its legs trying to stand. It’s the same principle that explains why large vehicles perform poorly in crash tests and why a plane the size of a cruise ship would have a wingspan too wide to fit on any airport's landing strips (not to mention entirely uneconomical due to fueling costs).
Software is no exception to this law of nature. Complexity grows exponentially. While native apps have weathered this storm well due to their preloaded UI, the web’s on-demand nature has translated to ever-increasing performance issues and crippled user experiences.
The only path that can lead to the next generation of the web involves leaving behind JavaScript entirely! web4 is fundamentally about building webapps with zero JavaScript. That way, webapps are free to grow to any level of sophistication without needing to pay the on-demand performance tax.
It does this by bubbling DOM events up past the browser, all the way to the server. Event handlers can run server-side in any language (preferably one optimized for latency and multi-threading). Lastly, in a move similar to Cocoa & Quartz 2D, the server can push “drawing commands” back to the browser to manipulate the DOM from the other side of the wall. This is an application-layer protocol called HTTP/X. It was covered earlier in this series at Zero API Necessary and comes with many benefits, including language optionality, a payload that never grows regardless of app size, no JSON API to build, and a much-simplified programming model since your logic isn’t forced to straddle both sides of the client/server wall.
Interestingly, the catalyst causing this paradigm shift doesn’t come from software or hardware innovations – it’s coming from infrastructure investments.
Ubiquitous low latency has been achieved globally
“Yeah, the speed of light sucks.”
– John Carmack
A slow tectonic shift has been quietly taking shape and two separate land masses have just collided forming a brand new continent called web4. Usually generational shifts in technology attribute their beginnings to the invention of some brand new thing that unlocked a previously impossible use case. For web4, this is not the case. The change was gradual and it snuck up on us all.
The birth of web4 is marked by the tipping point where it became faster to manipulate the browser’s DOM remotely rather than locally. Specifically, the latency improvements in last-mile networking combined with the explosion of cloud locations have taken the performance profile of a typical webapp and flipped it upside down.
The Edge
The expression The Edge is used in a wide variety of contexts so it’s probably worth defining, in precise terms, what it means in the context of web4 and how it differs from The Cloud. Where it gets a little confusing is that the expression “cloud provider,” serves as an umbrella term encompassing both The Cloud and The Edge.
- The Cloud runs your business logic on origin-servers in one centralized region so it can be located near your data.
- The Edge runs your UI logic on edge-servers across many distributed zones so they can be located near your users.
Note:
Architects will often add redundancy to The Cloud with a warm/standby presence in multiple centralized regions but that’s referring to failover-architecture, not distributed-architecture which is the focus of this essay.
The Edge (sometimes called zones or local zones), usually offer a subset of services compared to upstream regions, but importantly, they all offer fully-functional elastic compute (like EC2).
Over the past 5 years, cloud providers have been pouring billions into building out The Edge. An estimated $232 billion in worldwide spending for edge computing is expected for 2024, an increase of 15% compared to 2023. AWS has grown from 1 local zone in 2020 to 34!
Broadband
March 2023 marks an important milestone in the planet’s last-mile internet infrastructure. According to Ookla SpeedTest, our planet recently reached a median last-mile latency in the single digits: 9ms!
The last-mile is the most expensive and laborious part of deploying broadband infrastructure by a wide margin. It’s much like exiting the highway and driving on slower, disorganized back roads. For the most part it represents the time it takes to round trip a single networking packet from your device to the edge of the internet, in this case, the nearest Ookla SpeedTest instance. Since there are over 16 thousand of these SpeedTest servers sprinkled across the globe, it’s the best dataset we have for understanding the floor latency for real-world broadband experience across all countries.
In other words, 9 ms represents the minimum tax for doing anything interesting on the internet. However, once a networking packet is past the last-mile, it’s still bound by the speed of light.
Flipping the client-side equation upside down
Let’s talk about the number 16.7. While some web devs might not find it familiar, game devs obsess about it. It’s the number of milliseconds they have to execute all their logic and rendering before the next frame must be ready for display on a standard 60 Hz monitor. Rendering your game faster than 60 FPS is a great accomplishment but technically those extra frames are just thrown away if your screen cannot support it.
If we think of building webapps like building video games, and we consider that the edge of the internet is now only 9 milliseconds away, how much further is it to the nearest elastic computing resource and could it all fit within a 16.7 millisecond budget?
The speed of light in long haul fiber optic cable is slowed by 1/3 due to its refractive index plus network switching has its own overhead. We could calculate coast-to-coast round-trip times like these two very fun articles, or we can just look up the timings to get real-world results in practice. Evidently, a 7.7 ms round-trip ping equates to roughly 350 miles – the distance between SF and LA.
Here is a latency map illustrating both the growth of The Edge and improvements in last-mile latency. As recently as 2020, last-mile latency was as high as 24 ms and AWS had only a single local zone (in addition to 23 full-service regions). Today, last-mile latency has improved nearly 3x and AWS offers elastic compute in 65 unique locations. Check your pings at aws-latency-test.com.

In other words, ubiquitous low latency has been achieved globally.
Technically, round-tripping in under 16.7 ms isn’t a hard requirement. 100 ms should still feel instant according to Jakob Nielsen's Usability Engineering but he’s describing something more akin to reacting to the click of a button not necessarily a pro-gamer sensitivity to fluid frame rate. The reason the 16.7 ms threshold is significant is because it represents “peak performance” where anything faster is thrown away. Your screen is the new bottleneck now making it impossible for a client-side app to be faster than an edge-side app.
It’s definitely worth covering the current state of cellular technologies. 5G is remarkable not only because of its bandwidth but also because of its improvements in last-mile latency. While 4G suffers from an “air latency” between 50-100 ms, 5G brings that down to 8-12 ms! Meanwhile, 5G rollouts, which began in 2019, are progressing at a blistering pace. As of Q1 2024 the US is at 76.7% while countries like China and South Korea are already above 90%. Meanwhile, in order to free up spectrum for 5G, the FCC outlines the complete shutdown of 3G by 2022. (It’s strange to still see the option for simulating 3G in Chrome Dev Tools; it’s no longer possible to force 3G from the iPhone.)
| Cellular Generation | Latency (milliseconds) |
|---|---|
| 2G | 300 - 1000 |
| 3G | 100 - 500 |
| 4G | 50 - 100 |
| 5G | 8 - 12 |
The game is changing beyond cellular coverage too. Satellites now connect the most remote locations of the planet and Starlink, just this month, announced a new internal median latency of 28 ms.
Both broadband and cloud infrastructures have grown so much that it feels like The Edge has finally arrived at our doorstep. Like a puddle of spilled Kool-Aid that has spread far enough to stain your carpet, The Edge is now a permanent extension of the web browser. Architecturally, it makes sense to conceptualize the two as the same component now.
Welcome to web4. This changes everything.
Prove it with numbers
Stay tuned. Work in progress...
Common web4 misconceptions
Does this mean web4 will replace web2?
No. web2 did not replace web1 nor did web3 replace web2. True, incrementing version numbers usually implies deprecation but that is not the case here. Each new generation of the web represents a new species forked from first principles instead of evolving a preexisting generation.
| Generation | Species | Logic |
|---|---|---|
| web1: the read-only web | Static webpages | Server-side |
| web2: the read-write web | Dynamic webpages | Client-side |
| web3: the zero-trust web | Blockchain contracts | Decentralized |
| web4: the real-time web | Rich webapps | Edge-side |
What replaces JavaScript?
Ideally JavaScript is replaced by, not just one, but a multitude of languages. Since web4 runs your UI logic on The Edge instead of in the browser, it unshackles developers from browsers’ language-monopoly.
These web4 languages won’t be the usual scripting languages popular in web2, however. Due to the critical importance of latency, web4 more closely resembles high-frequency trading systems or MMO games, so web4 will more likely be composed of lower-level, multi-threaded, low-latency languages like C#, Java, Kotlin, Swift, Go, and Rust. This is covered in deeper detail at Zero Horizontal Tax.
To reduce fragmentation as much as possible, web4 should ideally share the same language-agnostic templating syntax across all languages though. ZeroScript is basically just HTML that’s been adapted to work with any language. This is covered in deeper detail at Zero New Syntax To Learn.
To be clear, web4 isn’t predicting the death of JavaScript, just that it’ll be rare to see it running on The Edge. In fact, since web4 is strictly about the UI layer, it’ll likely be common to see it connected to preexisting JavaScript backends running on origin-servers located back in The Cloud. More about thriving on The Edge can be found at Zero DOM and Zero Memory Allocations.
Why ZERO JavaScript? Not even a little?
Some might be incorrectly picturing a hybrid scenario where HTML comes from the server and JavaScript is still written in small quantities like the web1/MVC/jQuery days. However, the HTTP/X protocol strictly forbids running custom JavaScript in the browser since it will eventually result in state-inconsistencies. In web4, state management becomes the responsibility of the edge server and since it’s only allowed write-only access to the DOM and cannot read it from afar, the browser’s local state must not be allowed to drift or else it will result in rendering inconsistencies.
Won't there inevitably be a JavaScript-flavored web4?
According to Atwood’s Law, yes, it is inevitable – “any application that can be written in JavaScript, will eventually be written in JavaScript.” Unfortunately it’s likely to go poorly. Like any technology, web4 is no silver bullet, and comes with tradeoffs that are self-defeating to ignore. For example, event handling will have networking overhead and its wire protocol can be 100x more chatty than typical HTTP. Therefore, what web4 needs most for success is a low-latency, multi-threaded, single-process runtime with large amounts of shared memory offering manual memory-management primitives to reign in excessive garbage collection. JavaScript offers none of this; and it never will or else it would, according to Surma, “break everything and set it on fire.” (Technically he was describing Web Workers but that shares much in common with web4).
In addition to language shortcomings, the JS community will inevitably bring along their familiar web2 tooling and coding patterns. Others have already proven that this approach is doomed to fail when operating from The Edge. The fastest JS frameworks, even after stripping out all the overhead, have render latencies measured in milliseconds when they need to be microseconds or even nanoseconds. Some popular frameworks can’t even clear the 16.7 ms threshold. When put under a light load, even a hello-world app’s median latency can quickly climb to hundreds of milliseconds.
None of these comments about JavaScript are meant as criticisms as they have served web2 well in the past and will continue to do so in the future. The important takeaway is that web4 is an entirely different species with a rather opposite set of requirements. While web4 promises apps that are faster than web2; trying to build web4 apps using web2 tech is guaranteed to be slower than either generation by a painfully wide margin. Using JavaScript to build web4 would be as nonsensical as trying to get a rocket into space using a container ship propeller.
How is web4 different from running a headless browser in the cloud?
For starters, that approach would be prohibitively expensive and it needs to be roughly a million times more efficient with both CPU and RAM. My own laptop has trouble keeping up with my tabs sometimes. A browser does so many incredible things to provide the incredible experience it does. The only thing a web4 server must do is shoot HTML down the wire as fast as possible and react to DOM events with JS commands over a WebSocket. This is shockingly little responsibility. There is zero DOM to construct and diffing can be done in O(1). In fact, a web4 server probably has more in common with Varnish than Nginx.
How is web4 different from a thin client?
web4 does resemble a thin client in one way: 100% of the UI logic lives on the edge-server and it is in full control while the browser simply does what it’s told. There are no fetches ever; if the browser needs data, the edge-server will push it over the WebSocket.
web4 is an interestingly pure implementation of the Unidirectional Data Flow design pattern. State is separated from UI. UI is a function of state. Only UI can generate an event (DOM events). And only a change in state will cause the UI to mutate. The unique part of web4 is that this state/event boundary is network-separated.

What makes web4 different from a thin client is that most thin clients (like VNC) perform rasterization server-side and try their best to push millions of pixels over the network to a dumb terminal that has zero rendering responsibilities (except for the mouse interestingly). web4’s “terminal” may be the web browser but it isn’t technically “dumb” since it’s responsible for rendering HTML, handling all inputs, applying all CSS and things like animations still happen locally and remain buttery smooth and GPU accelerated.
How is web4 different from MVC or a SPA?
The simplest distinction between each species is where you put the network boundary; shown here with a dotted line. (Forgive the oversimplifications here, web1 and web2 have many hybrid options.)
- web1 (MVC): state and UI live on the server
- web2 (SPA): state and UI live in the browser
- web4: state lives on the server, UI lives in the browser

How is web4 different from SSR or Server Components?
With web4, there’s zero hydration. It just sends basic, old fashioned HTML over the wire. After the GET completes, it establishes a WebSocket connection so the server can handle events and manipulate the DOM remotely.
With web2 frameworks, hydration is a necessary evil in order to be isomorphic (capable of running on the server and the client). Isomorphism does offer flexibility but it comes at a great cost in complexity. It sends the site to the browser twice, once as HTML and again as JavaScript. When used right it might speed up a typical web2 TTI, but it will never be faster than web4 since web4 also comes from The Edge but requires executing zero hydration logic and downloading zero application code.
Hydration is a horrible workaround because web frameworks don't embrace how browsers actually work.
— Miško Hevery (Builder.io/Qwik) (@mhevery) April 13, 2022
Yet somehow we have turned it into a virtue.
Hydration is a hack to recover the app&fw state by eagerly executing the app code in the browser.
That is why your app is slow.
How is web4 different from partials/fragments/islands?
Generally, web4 takes a more surgical approach towards updating the DOM. It adjusts individual elements’ nodeValues instead of bluntly swapping out large chunks of HTML.
Does that mean adding WebSocket-based “live views” qualifies as web4?
Not by default, no. At the risk of oversimplification, web2 and web4 operate like a dichotomy and can be thought of as two ends of a spectrum where, at one end, state and logic run 100% in the browser and at the other end, state and logic run 100% on the server. Many tools qualify as hybrids, positioning themselves somewhere halfway between these two worlds but an app wouldn’t be considered web4 until it fully eschewed all client-side state and logic. Also it’s worth noting that web4 doesn’t stop at merely operating on the server side. It’s fundamentally meant to be an edge-native concept which requires a major shift from request/response protocols to bi-directional protocols and needs local-first approaches to data to take full advantage of The Edge.
So what then?
Webapps have failed to keep pace with native apps because JavaScript is intrinsically limited by its payload problem and there is no way to fix it. It’s been a long time coming but web4 is largely about harnessing the power of The Edge which has finally arrived at our doorsteps. The Edge ends JavaScript’s monopoly on dynamic webapps and opens the floodgates for competition from other languages like C#, Java, Kotlin, Swift, Go, and Rust. To prevent fragmentation in the web4 community, each language shall share a common templating syntax called ZeroScript designed to be both language-agnostic and edge-native. This will create a simpler, richer, more real-time web.