
Zero Horizontal Tax: web4

This is part 3 of a 12-part series called Distilling the Web to Zero. The web is far from done improving - particularly as it pertains to building rich web applications that are, to users, developers, and businesses alike, more desirable than their native-app counterparts. This series is prefaced by defining the biggest challenges on the road towards that goal and the 12 essays that follow explore potential solutions using concrete examples.
Why is the web stateless? These were decisions made in the Internet’s formative years that we’re now stuck with, like it or not. Could that decision ever be reversed? If the web’s foundation was built to be state-FULL instead, in what ways would our webapps be better? What would it take to rewrite that history and would it be worth it?
Why is the web stateless?
Many would answer this question with a response about statelessness being a critical component and necessary tradeoff for horizontal scaling. But the need for horizontal scaling didn’t come until later as a defining feature of the web2 era. The web has been stateless by default since the first web1 days.
web1: The early web was scripted
The web was born and grew up on Unix-like systems and naturally adopted a very “POSIX approach” to serving a webpage. The mental model of receiving an HTTP request and outputting a response very closely resembled the anatomy of executing programs from the command line: there were clearly defined inputs, pipeable output, and a clearly defined termination. This is why early webservers (e.g. Apache) would spawn a brand new process for each request and terminate the process after outputting the response. This was clearly designed for familiarity and convenience and not for efficiency. This “reuse nothing” approach had a large influence on the early protocols of the web – mainly embracing statelessness at its core.
These patterns also explain why the early web was dominated by scripting languages like Perl (via CGI) with other scripting languages soon following such as PHP, Ruby, Python and eventually JavaScript. This pattern of using scripting languages was not a coincidence. They were approachable, easy to use, the tooling was often pre-installed, and they more naturally fit into the typical workflow of the time.
Another contributing factor for the web’s propensity for scripting languages was the fact that most CPUs at that time were still single-core. Reaching for lower-level, multithreaded languages of the time (like C++) was needlessly complicated and overkill for what was, at the time, essentially a script full of print statements for HTML tags going to standard output which got passed to the web client instead of being shown in the terminal window.
web2: Horizontal scaling got locked in as the de facto standard
In the early 2000s the web2 era began, and horizontal scaling solidified as the de facto standard architecture of the web which further perpetuated the web’s stateless nature. Three main forces played a role here:
- Hyper-growth
The explosive growth of the web2 era outpaced the growth of hardware and adapting to “web scale” meant splitting your workload across more than one machine. During this early 2000s era, CPU speed was measured in megahertz and RAM was measured in megabytes so horizontally scaling was the only option to handle such a load. While hardware capacity would eventually catch up to “web scale,” these stateless patterns codified beforehand. - Moore’s Law died
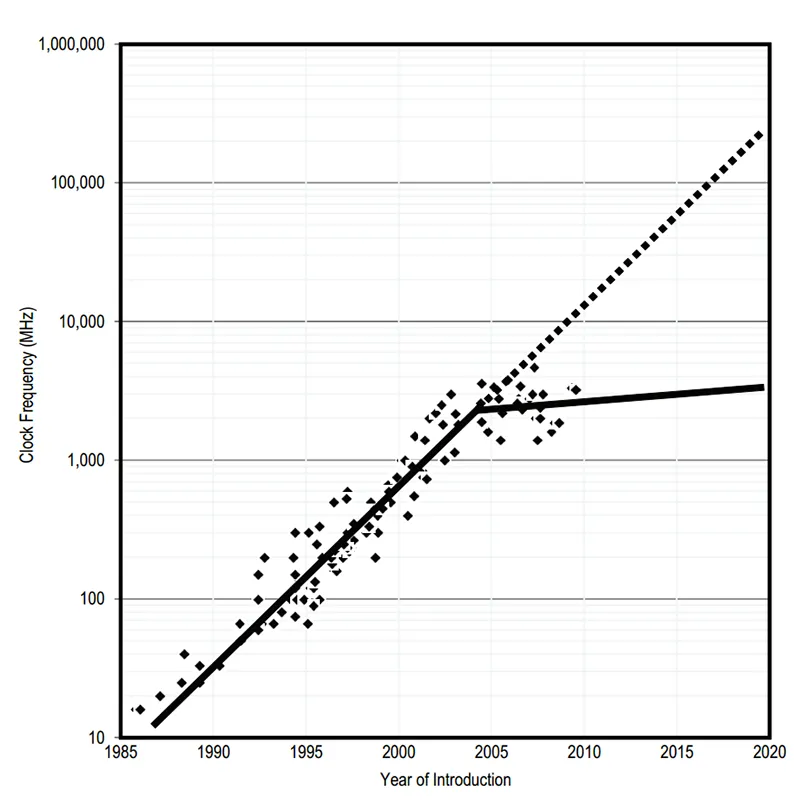 Some argue that Moore’s Law died in 2005. However this event went mostly unnoticed since the industry compensated by introducing more cores into each CPU. Some languages and runtimes adapted by way of multithreading but most scripting languages (which powered the vast majority of websites) were not designed to handle a multithreaded use case. Regardless, this didn’t matter since the web’s stateless protocols and horizontal architecture made it trivial to take advantage of multiple cores by simply load balancing across multiple processes in lieu of wrestling with threads. This came at the cost of being able to share RAM’s memory space between processes but it was of no consequence due to the web's stateless nature, that data was already being immediately discarded after each response; session-state was already being managed off-machine. Thus we kicked the can further down the road of statelessness.
Some argue that Moore’s Law died in 2005. However this event went mostly unnoticed since the industry compensated by introducing more cores into each CPU. Some languages and runtimes adapted by way of multithreading but most scripting languages (which powered the vast majority of websites) were not designed to handle a multithreaded use case. Regardless, this didn’t matter since the web’s stateless protocols and horizontal architecture made it trivial to take advantage of multiple cores by simply load balancing across multiple processes in lieu of wrestling with threads. This came at the cost of being able to share RAM’s memory space between processes but it was of no consequence due to the web's stateless nature, that data was already being immediately discarded after each response; session-state was already being managed off-machine. Thus we kicked the can further down the road of statelessness. - The Cloud was born
The timing of the cloud was no accident. Since the web chose to adapt to this brave new world of concurrency using processes instead of threads, from an infrastructure standpoint it was cheaper and easier to load balance across multiple smaller virtual machines than it was to take full advantage of a single giant server. For two decades, the cloud has sold us our pizza by-the-slice because that was all our scripting languages could eat. And businesses loved the control of being able to elastically match demand regardless of the hidden costs of the “horizontal tax.” Interestingly, these thinly sliced VMs had the side effect of concealing just how powerful raw server hardware had become over the span of 20 years. Eventually hardware DID catch up to “web scale” but by the time it did, the by-the-slice cloud already occupied the mindshare of the entire software industry.
To recap for a moment, the stateless-first nature of the web has been entrenched by our protocols, languages, software patterns, hardware, and infrastructure. Statelessness is a core tenet of the web but after learning that the backstory of this decision was grounded in convenience, poor timing, and might not even be necessary anymore due to unrecognized paradigm shifts in hardware and global networking infrastructure, does it make anybody wonder… What would the web be like if it were state-FULL first? If “good is the enemy of great”, does that mean we are settling for a mediocre web? Case in point, why do native apps even exist? They are proprietary walled gardens controlled by mega corporations. By all means, that seems like it’d be the inferior option compared to the open web. However, there’s clearly something about native apps that users gravitate towards. Clearly there’s something about our web apps that falls short. Each passing year we’re told THIS is the year of the PWA yet nothing ever changes. This will forever be the case too unless something fundamental about the way the web works is changed in a drastic manner.
“Good is the enemy of great.”
– Jim Collins
What if the web was state-FULL?
For starters, what exactly is The Stateful Web?
In short, it means that state is a server-primitive, not a browser-primitive. This seemingly tiny change permeates rippling effects to every corner of how we build things on the web. This is why it isn’t sufficient to simply “retrofit” a beloved SPA framework for duty on the server. This would be perpetuating all the same antipatterns from the past era. The Stateful Web is about rethinking the Internet from first principles. The Stateful Web is web4.
Here’s another way to conceptualize how The Stateful Web is different from the various eras of the Internet that came before it. The key takeaway here is that each new era of the web was sparked and fueled by a radically different software architecture.
| Era | Enabling Architecture | Species |
|---|---|---|
| web1: the read-only web | Distributed | Static webpages |
| web2: the read-write web | Horizontal scaling | Dynamic webpages |
| web3: the zero-trust web | Decentralized | Blockchain contracts |
| web4: the real-time web | Vertical scaling | Rich web apps |
Note:
Firstly, this does not imply that it was impossible to build a particular species before its defining era, just that it was the architecture that made it mainstream, the default outcome; it was the enabler of patterns.Secondly, each new era of the web is NOT about replacing the era before it, but instead it’s about welcoming something new. Each era is about the birth of a brand new species, waiting to spring to life, but constrained by the predominant architecture of the era before it.
The real-time web is about visiting a website that doesn’t feel like something that came out of a database. The real-time web isn’t about people leaving artifacts behind for other humans to stumble upon later. Instead, it’s about what's happening right now, as if each website was its own MMO video game. It’s instant, it’s about the now, it’s about communities – but not what’s been done in the past, it’s about being together. It’s going to the stadium with your friends instead of watching the game at home. It’s going to the farmer’s market instead of ordering from a catalog. It’s the serendipitous watercooler conversation, not the rigid video call agenda.
What are the architectural benefits of The Stateful Web?
-
Massively shared state
Start with declarative/reactive programming where mutating state causes the UI to react to its changes. Very powerful. Very productive. The Stateful Web adopts the same model but does so at a system-level in the backend instead of at the frontend in the browser. Imagine if reacting to state-changes wasn’t relegated to only one browser at a time but rather your entire system as a whole. The state used to render and mutate one user’s browser is the same state used to render and mutate everybody’s browser. In the Stateful Web, data is never stale or out of sync. State doesn’t need to be copied over and over repetitively for each new request but rather held in RAM where it can be massively shared with other sessions and reacted upon. The refresh button becomes obsolete, and real-time, collaborative apps are no longer challenging to build but instead become the status quo. -
Data is no longer inert
Horizontal data must remain largely inert, held captive, still, and centralized so it avoids the dreaded staleness/consistency issues that come with horizontal architectures. When your data is separated from your compute (whether it’s a separate server or even a separate process) it puts limitations on what kinds of magic can be done compared to bringing your compute together with your data in the same process. -
Local-first becomes the default
This plays a major role in the illusion of zero latency (which is far more common in native-mobile apps). In an architecture where data isn’t compulsively thrown away after every request, a new paradigm emerges. In this architecture, the UI is shown as a FIRST step, without any waiting, before fetching any data. Once the data is received the UI can naturally react to it and update. This happens whether the data is cache-miss or even stale but the UI is always displayed with zero waiting. Since The Stateful Web takes hard dependencies on stateful protocols (like HTTP/X), pushing changes later, after the initial request/response is completed, becomes commonplace. This plays a major role in killing “the white screen of death” – waiting to navigate from one page to the next, a problem which doesn’t exist in native-mobile. Local-first is also useful in the opposite direction. Optimistic concurrency gives the impression of zero latency by updating the UI first before any database transactions are completed, and reacting to errors in the event of any failures. While some are already doing this today, it's rare due to the difficulty level of fitting it into a web2 architecture. -
Geographically distributed
web2’s ephemeral nature imposes geographic limitations since “computing in edge workers in the absence of data makes applications slower” Since web4 is local-first by default, context isn’t discarded and rebuilt between each and every request, suddenly business logic isn’t required to be located within milliseconds of its various data stores. In fact, web4’s business logic should be spread out geographically by default, making it like a CDN for business logic instead of static content.
What must change to reach web4?
Justifying the version bump in web4 implies not only sweeping changes to best practices but also breaking changes that are not backwards compatible. For example, web3’s zero-trust paradigm was only made possible with the introduction of blockchains. Trying to use a traditional database for that would be completely missing the point.
web4 and web2 are primarily differentiated by their approaches to speed:
- web2 is about unbounded capacity (horizontal scaling)
- web4 is about peak performance (vertical scaling)
Every architecture’s benefit comes with tradeoffs.
- Horizontal architecture offers nearly limitless capacity but it comes at the cost of the “horizontal tax” imposed on each request.
- Vertical architecture offers a step function improvement in speed by eliminating the “horizontal tax” but it puts a ceiling on maximum capacity, i.e. the limitations of a single machine.
It is the presence or the absence of the “horizontal tax” which separates web2 from Web4. To be explicit: it makes them mutually exclusive – opposites in many regards.
Eliminating the “horizontal tax”
The “horizontal tax” is the overhead that comes with statelessness – every HTTP request must re-fetch or re-query the complete set of data needed to render a single page and then immediately discard that data once the response completes. This is a necessary overhead in the name of data consistency since the very next request might be handled by an entirely different machine. Granted, there may be a caching layer but this doesn’t eliminate the horizontal tax. The horizontal tax is what forces your data to remain inert, prevents it from being shared on a massive level, makes local-first development exceedingly difficult and anchors your infrastructure to a single region.
RAM is 5,000x faster than a network round trip in the same data center. Vertical architecture revolves around this core principle – when you can guarantee that a workload will never need to be split across multiple machines, the speed gains aren’t just a 20% boost here or a 50% bump there. Response times can be transformed from milliseconds to nanoseconds. Not microseconds… nanoseconds! Couple that with the fact that data in RAM is active data, not passive inert data forced to be still and stagnant in some cache. This enables it to be massively shared and used as reactable-state. Lastly, computing in the presence of data unlocks edge locations that are mere milliseconds away from its users.
Why now?
Vertical architectures aren’t new, just uncommon in web development. As one example, the intense demands of video games (particularly MMOs) necessitated this strategy long ago. The reasons the web matured the way it did are covered above so why is now finally the era of web4? What has changed?
It basically boils down advancements in 3 categories:
-
Server hardware
For 20 years the cloud has been selling web developers their compute “by-the-slice” so an entire generation of web developers are largely unfamiliar with the full potential of a single server. While they understand that the risks of a vertical architecture are about hitting the ceiling of a single machine with no ability to scale out, what most don’t know is exactly how high that ceiling has been raised over the past 20 years. StackOverflow has shown the world that this ceiling is likely much higher than anybody will ever need (unless you’re a FAANG company). StackOverflow is a top-50 most trafficked website and they can famously handle their entire traffic on only one web server if they choose. -
Global networking infrastructure
Cloud providers are investing billions in growing their capacity. But recent trends are not only about making their regions larger, they’re becoming geographically diverse too. These new “smaller zones” might not offer every SaaS service found in larger regions (like S3), but spinning up a server IS one of those services. What’s huge is instead of a region being hundreds of milliseconds away these zones are sometimes only a few milliseconds away from users. (I’m seeing 6ms from where I’m writing this.) CDN providers are approaching the same destination from the opposite direction. It used to be the case that “the edge” was just about caching your static content close to your users. Now they are offering compute-related services across their expansive network. -
Modern multithreaded languages
The mystery of how much load a single server can take is only halfway related to the first point – server hardware. The other half can be attributed to the prevalence of scripting languages. Reaching the peak performance of a single machine (without process-sharding) cannot be done with single-threaded, interpreted languages. Peak performance requires utilizing every core. Doing so while sharing RAM, requires you to multitask with threads, not processes. In the web’s early days the best option for this was C++, so adopting scripting languages made sense (for reasons outlined above). These days new multithreaded languages like Java, C#, Go, and Rust are far more approachable; they do not have the same barrier to entry as C++ and can provide orders of magnitude better performance.
Why is peak performance so critical for web4?
Is striving for peak performance just a game of engineering-naval-gazing? No! The tools we use to build web2 simply do not work in a web4 context. Let’s talk numbers. Consider a web4 use case where there are 20,000 concurrent users each connected to the same server. If a piece of state that’s shared globally amongst them all is mutated, it would require re-rendering each user’s content, detecting each difference and pushing commands to each of their browsers to update the UI as necessary. Remember, due to the constraints of sharing memory space this must all fit on a single machine.
web2 frameworks have render-latencies that typically range between 50 and 250 milliseconds. Doing that 20,000 times, once for each user, would require up to an hour of CPU time to handle that single state mutation! This is clearly a bridge too far.
web4 frameworks need to be able to render, not just across multiple CPU cores but with speed-conscious languages using radically faster rendering algorithms. Ideally, it should be able to support 60 FPS for each user (specifically: 60 state mutations each second, capable of broadcasting unique instructions to each of the 20,000 connected browsers). Handling 20k state mutations 60 times per second comes out to 1,200,000 responses per second. On a 64-core machine, this would require an average time-to-render (including network-write) of 53 microseconds. This is a 1000x difference in performance tolerances between web2 and web4.
Is this even within the realm of reality? With a little bit of work, yes.
web4’s first tech stack: xUI
I hope to one day see web4 tech stacks across a multitude of languages. Additionally, I hope they all use ZeroScript as their templating syntax which has been designed to work well with web4 while, at the same time, reducing the framework fatigue that’s common in web2 ecosystems. (ZeroScript is also covered earlier in this series.)
This series kicks off this new web4 era using C# running on .NET with ASP.NET Core. Instead of Razor/Blazor, though, this series explores the development of a brand new, from-scratch view engine called xUI. It’s designed from the bottom up to take the most advantage of massively-shared state in a declarative/reactive paradigm. Here’s a breakdown of the rationale behind choosing this tech stack:
-
Familiarity for TypeScript developers
TypeScript was heavily influenced by C#. In fact, these two languages share the same creator. For curious web2 developers that already know TypeScript, reading C# should come naturally and learning to write C# should come quickly. -
Familiarity for video game developers
Architecturally, this new web4 species shares more in common with a typical video game than a typical webpage. It’ll be just as important to attract expertise from the video game industry as from web dev circles. While C++ remains the most popular language in video gaming, C# clocks in as 2nd, largely thanks to the ubiquity of Unity. This should hopefully encourage the transfer of these skill sets into the web4 community. -
Cross platform
xUI has long term plans beyond just web development – they include native mobile too. In fact, web4 derives more of its development philosophy from the mobile space than the web space. Until just recently, C# was the only language that could span across iOS, Android and the desktop (note: Kotlin/Native has recently joined this elusive club too). Apple is notoriously protective of iOS, which is why there is no JVM on iOS (citing security concerns). Apple explicitly disallows the execution of dynamically generated code. This includes any bytecode and all scripting languages. Some projects skirt around this restriction by marshaling over to Apple’s WebKit sandbox which comes with large performance penalties. C# gets around this by using its Ahead of Time (AOT) compiler to compile the managed code which produces a native iOS binary that can be deployed to the App Store with Apple’s blessing. -
Versatility
The versatility of the .NET platform is a marvel. C# is a language that is safe by default making it very approachable for newcomers, while at the same time not sacrificing the ability to easily drop into an “unsafe context” for those low-level gains when needed. The compiler has incredible, modern features too like source generators (which will be useful for implementing ZeroScript support and the ability to target not just dynamic libraries (like DLLs) but ahead of time compiling (Native AOT) and WebAssembly. -
Speed
A massive amount of effort has been invested in making ASP.NET Core and Kestrel as efficient as possible. With web4, performance must be prioritized over convenience which limits language-choice. Unlike web2, capacity issues aren’t fixed by adding more machines, web4 has strict performance budgets that cannot be neglected or else you hit the ceiling with nowhere to go. Using a web server that has unnecessary overhead is a non-starter in web4. A great source of the world’s fastest web servers can be found on TechEmpower’s Benchmarks. There you’ll notice that the top options all seem to top out at roughly 7M req/sec. This is because they’re maxing out the machine by saturating the 10Gb network card, not the CPU. Achieving this milestone without any process sharding (so the memory space can be shared) should be table stakes for any web4 stack. From a language standpoint, it is possible for C# to perform in the same league as system-level languages like C++, Go, and Rust if you’re meticulous about managing memory manually and taking advantage of zero-copy writes… but that’s a story for next time. -
Open source
Microsoft has gone through a bit of a renaissance over the past decade. Ever since they sacrificed their old cash cow Windows, so they can bet the farm on their new cash cow Azure, it’s been not just a boom for their business, but transformative for their dev tools. Microsoft and developers have never been more aligned than now. Plus their dev tools are very well suited for this kind of use case (just ask the legendary John Carmack). -
Modern and innovative
It might be over 20 years old but C# continues to be a modern language. The innovation is strong there. Wonderful new concepts like async/await and LINQ were forged in C# and new features aren’t just frequent but fleshed out in the open on GitHub. .NET is a multi-language runtime too; check out F# as an example of a brilliant functional language that shares the same .NET runtime.
Wrap it up already
I’ve come to dislike building for the web. It feels like it isn’t reaching its full potential. I wish it felt more like a mix of building native apps and video games. Doing so will feel like hitting the reset button on nearly every best practice though. Maybe that’s a good thing? web4 is basically the opposite of web2 71.8% of the time.
Artifacts
- Source code: github.com/xui/xui
Member discussion